FabasedVC: Voice Conversion with Text Modality Fusion and Phoneme-Level SSL Feature
Contents
- Abstract
- Features introduction
- Demos -- VC Experiment
- Demos -- Duration Experiment
- Demos -- Ablation
1. Abstract
In voice conversion (VC), it is crucial to preserve complete semantic information while accurately modeling the target speaker's timbre and prosody.
This paper proposes FabasedVC to achieve VC with enhanced similarity in timbre, prosody, and duration to the target speaker, as well as improved content integrity. It is an end-to-end VITS-based VC system that integrates relevant textual information, phoneme-level self-supervised learning (SSL) features, and a duration predictor.
Specifically, we employ a textual feature encoder to encode attributes such as text, phonemes, and tones. We then process the frame-level SSL features into phoneme-level features using two methods: average pooling based on each phoneme's duration and an attention mechanism. Moreover, a duration predictor is incorporated to better align the speech rate and prosody of the target speaker.
Experimental results demonstrate that our method outperforms competing systems in terms of naturalness, similarity, and content integrity.
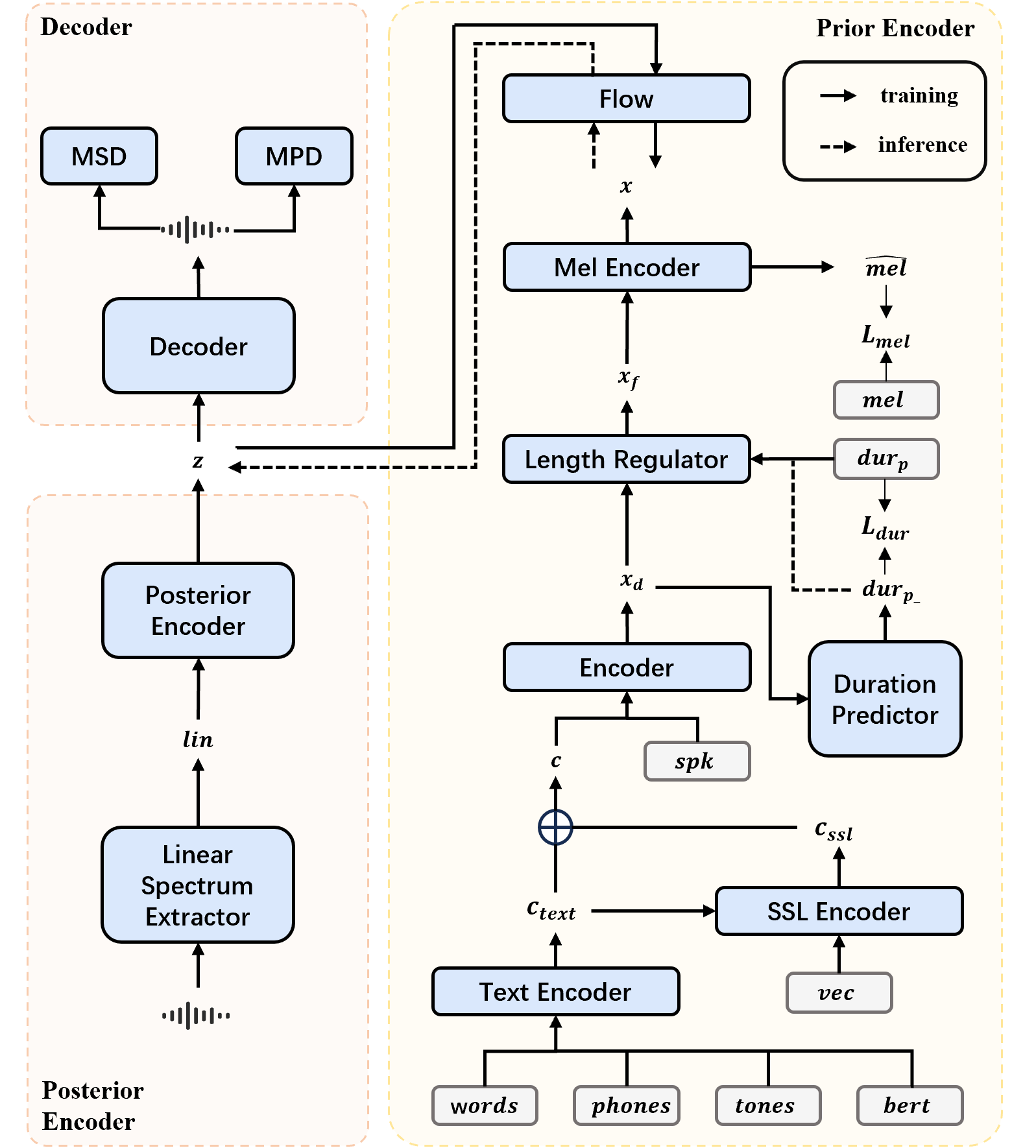
2. Features introduction
Words, Phonemes, and Tones are obtained through ASR models and related annotation tools, representing the textual content, phonetic information, and tonal characteristics of speech, respectively. Tonal information refers to the pitch variation patterns of a syllable during pronunciation; since Chinese is a tonal language, this feature is not applicable when processing non-tonal languages such as English. Some speech voice synthesis systems employ BERT features of text to enhance semantic information. Similarly, we derive WordsBERT features from the Words feature using BERT to further enrich the information.
A forced alignment annotation model can generate timestamps at the phoneme level of speech. By leveraging existing forced alignment annotation models and integrating them with speech data, as well as the Words and Phones features, we can extract duration information for each element of Words and Phonemes in the speech. By aligning this duration information with the frames of the spectrogram, we obtain Pframe and Wframe features, which represent the frame lengths corresponding to each character and character, respectively. The W2P feature indicates the number of phonemes associated with each character in the Words. The Speaker feature conveys speaker-related information linked to the speech, while the Contentvec feature refers to the disentangled SSL features extracted from the speech.
Due to certain limitations, we will not be demonstrating the WordsBERT and Contentvec features here; both are represented as Tensor vectors.
| Wave | Words | Phonemes | Tones | Pframe | Wframe | W2P | Speaker |
| _ 卡 尔 普 陪 外 孙 玩 滑 梯 _ | sil k a er p u p ei uai s uen uan h ua t i sil | 0 0 2 2 0 3 0 2 4 0 1 2 0 2 0 1 0 |
1 7 7 10 12 14 11 6 19 9 14 20 7 12 12 20 2 |
1 14 10 26 17 19 23 20 19 32 2 |
1 2 1 2 2 1 2 1 2 2 1 |
databaker | |
| _ 因 为 他 是 行 凶 者 _ | sil in uei t a sh iii x ing x iong zh e sil | 0 1 4 0 1 0 4 0 2 0 1 0 3 0 |
17 15 9 7 8 11 7 5 10 3 17 4 24 24 |
17 15 9 15 18 15 20 28 24 |
1 1 1 2 2 2 2 2 1 |
SSB0316 | |
| _ 楼 市 整 体 回 暖 步 伐 加 快 _ | sil l ou sh iii zh eng t i h uei n uan b u f a j ia k uai sil | 0 0 2 0 4 0 2 0 3 0 2 0 3 0 4 0 2 0 1 0 4 0 |
34 10 12 11 20 6 13 5 11 12 8 7 21 9 10 7 12 7 14 8 27 38 |
34 22 31 19 16 20 28 19 19 21 35 38 |
1 2 2 2 2 2 2 2 2 2 2 1 |
SSB1328 | |
| _ 三 万 七 千 一 百 七 十 一 点 六 五 _ | sil s an uan q i q ian i b ai q i sh iii i d ian l iou u sil | 0 0 1 4 0 1 0 1 4 0 3 0 1 0 2 4 0 3 0 4 3 0 |
22 10 14 21 8 11 7 17 12 5 12 12 9 7 8 13 5 13 5 10 30 22 |
22 24 21 19 24 12 17 21 15 13 18 15 30 22 |
1 2 1 2 2 1 2 2 2 1 2 2 1 1 |
SSB0993 | |
| _ 一 千 一 百 九 十 四 _ | sil i q ian i b ai j iou sh iii s ii sil | 0 4 0 1 4 0 3 0 3 0 2 0 4 0 |
17 19 5 10 14 5 12 7 10 7 7 9 27 25 |
17 19 15 14 17 17 14 36 25 |
1 1 2 1 2 2 2 2 1 |
SSB1759 |
3. Demos -- VC Experiment
1. aishell to aishell
| Source Speech | Target Speaker | FabasedVC(ours) | SeedVC | CosyvoiceVC | FreeVC | SOVITS-VC | PPGVC | VQMIVC |
2. databaker to aishell
| Source Speech | Target Speaker | FabasedVC(ours) | SeedVC | CosyVoiceVC | FreeVC | SOVITS-VC | PPGVC | VQMIVC |
4. Demos -- Duration Experiment
The average phoneme duration (phones/s) of the source and target speaker's speech before and after conversion.
Please note that the demo showcases sampled data from the experiment, while the average phoneme duration is the mean value obtained from all audio data throughout the entire experiment.
| Source Speech | Source Duration | Target Speech | Target Duration | Generate Speech | Generate Duration |
| 0.1238 | 0.1189 | 0.1233 | |||
| 0.1367 | 0.1303 | ||||
| 0.0983 | 0.1156 | ||||
| 0.1099 | 0.1209 |
5. Demos -- Ablation
| Source Speech | Target Speaker | FabasedVC | w/o SSL Pooling | w/o SSL Attention | w/o Duration predictor |